
Introduction
The AI and machine learning communities are seeing an unprecedented level of interest and investment. While new solutions seem to come into the market almost daily, AI engineers will tell you that building a highly performant model can still be challenging. To that end, we conducted a survey to understand the hurdles faced by NLP and ML engineers.
Key Takeaways
Demographics and Background
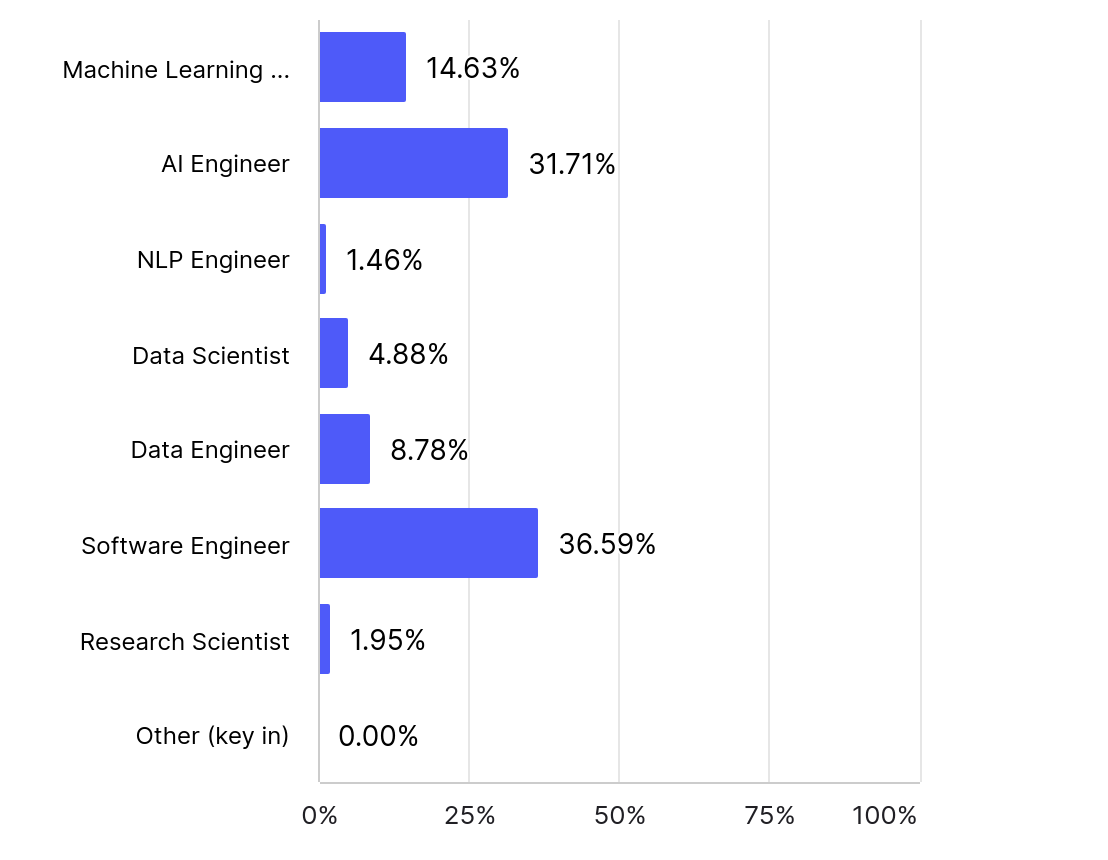
- Roughly a third of the respondents identified as "AI engineers," while another third held the title of "Software engineer." Only 15% identified of the respondents identified as “Machine Learning engineers,” indicating that software engineering jobs are increasingly beginning to include machine learning work.
Model Usage
- Respondents reported on working with different model types at the same time, including experimenting with both “classical” machine learning models and LLMs. API-accessible LLM models (such as GPT, Claude, and Gemini) are the most popular with roughly 80% reporting they’re working with them, while 69% reported working on predictive analytics models.
- This indicates a growing desire to find generative AI solutions to problems that are actually more suitable for traditional machine learning models, and is concurrent with our own experience at Orca.
Primary Challenges
- Data quality and availability (51%) and model accuracy and performance (46%) were reported to be the biggest areas of concern for respondents, with scalability coming in third.
- Within the context of model performance, consistency was reported to be the biggest challenge (70%), with latency coming in second.
- The ranking of these concerns stayed consistent across those working with classical and generative AI models.
- While cost is noted as extremely or very important by a majority of respondents, it is not the most pressing issue. Data quality and model performance are considered first-order problems, with cost being a theoretically important but secondary concern.
.png)
Qualitative Feedback
We also collected free form comments on challenges as well as respondents’ desires for new capabilities in model developments. A few themes emerged based on these comments:
1. Dirty, incomplete or biased data
A recurring problem is the presence of low-quality, incomplete, incorrect or biased which can significantly hinder the model-building process. Poor data inputs lead to poor model outputs and issues with consistency, making it difficult to trust the results.
- "Getting accurate data is a challenge, majority of the data is dirty."
- "Incomplete or inaccurate data can be a significant barrier to interoperability, put garbage in you get garbage out."
- "It's hard to find data that isn't biased or missing key pieces to train on."
2. Difficulty in acquiring enough data
Respondents often mention struggling to gather sufficient quantities of quality data for training their models. This could be due to limitations in access to data sources, the cost of acquiring data, or the lack of public datasets.
Quotes:
- ”Finding quality data in enough quantity to iterate is challenging.”
- "We have difficulty getting enough data for repeatable quality results."
3. Interpretability and transparency
Many respondents express the desire for models that are easier to understand, providing clear explanations for their outputs and decisions. This is especially important for building trust in AI systems and ensuring their practical use.
Quotes:
- "I'd like to see advancements in model interpretability and exploitability to ensure AI systems are transparent, understandable, and trustworthy."
- "I would like to see more accurate and transparent capabilities when building new models."
- "I would like to see advancements in model building that enhance interpretability, making it easier to understand how models make decisions."
4. Continual learning and automated retraining
Many users desire models that can automatically update and learn from new data, reducing the need for manual retraining. This capability would help models stay relevant and accurate as data evolves over time.
Quotes:
- "Intelligently automated retraining and compatibility with various platforms."
- "Continual Learning; AI models require continual updating and retraining to stay relevant and accurate as new data and information become available."
- "I would like to see improvements in the ability to integrate and interpret multimodal data (e.g., text, images, audio) seamlessly within a single model."
4. Adaptability to new data and changing environments
Several responses also called for models that can dynamically adapt to new and changing data or conditions without performance degradation. This included the need for models that can incorporate and update in real-time, allowing for live data inputs and dynamic decision-making based on continuously changing information.
Quotes:
- "More adaptability for the built models in terms of accuracy on the predictions."
- "Live data incorporation, feeding the model a specific livestream of data and having it live update its predictive results based on that data."
- "Online Learning: Models that can learn from streaming data, adapting to changing patterns and distributions."
4. Transfer learning and domain adaptation
Respondents also expressed interest in models that can transfer knowledge from one domain to another, making them more adaptable across different use cases and data environments.
Quotes:
- "Transfer Learning: Models that can adapt knowledge from one domain to another, improving generalization."
- "Advancing the explainability and transparency of complex models to ensure that their predictions and processes are easily interpretable and trustworthy for end-users."
- "I would like to see models become more adaptable and accurate across different domains."
Methodology
We surveyed 205 respondents using a combination of 20 structured and open-ended questions. Our participants ranged from junior to senior-level engineers, working on both generative and traditional machine learning models. The survey focused on model types, key performance challenges, and desired improvements to model capabilities.
Conclusion
The survey results underscore the critical challenges that ML/AI engineers face, particularly around data quality, model performance, and the trade-offs between cost and functionality. The desire for better interpretability, continual learning, and adaptability underscores the need for innovation in model development. It's also interesting to note that these challenges remained constant across both generative and non-generative model types. All of these insights provide valuable direction to those building the next generation of ML tools.
.png)



.png)




.png)
