
TL;DR
- Result: Orca's retrieval-augmented classification (RAC) models can adapt to data drift without retraining. We demonstrate how a model trained to analyze sentiment in airline-related tweets achieves a 7.3% accuracy improvement by simply editing its memories after performance degradation in a simulated real-world data drift scenario.
- Methodology: Orca's Retrieval-Augmented Classification (RAC) models use relevant memories to guide predictions, allowing real-time behavior updates without retraining. We trained a RAC model to classify sentiment in tweets about airlines and then simulated data drift by altering labels in a test-set subcategory. By simply updating memories, we recovered 5% accuracy, coming within 0.5% of a retrained traditional classifier's performance.
- Implication: Our results show that retrieval-augmentation enables classification models to adapt to changing requirements in real time with negligible tradeoffs in accuracy to retraining based approaches.
Understanding the Challenge
Recently, powerful transformer-based models, like BERT-family models, have revolutionized text classification tasks, including sentiment analysis. These models, which are pre-trained on vast amounts of text data, can be combined with simple linear classification heads and achieve state-of-the-art performance when fine-tuned for a given task. Their strength lies in their ability to understand the underlying semantics of text, capturing nuances such as sentiment shifts, sarcasm, and complex emotional expressions.
However, while fine-tuned transformer models excel in static environments, real-world sentiment analysis poses different challenges:
- Data Drift: Sentiment data evolves over-time, especially in dynamic environments like social media, where language trends shift, and new expressions emerge. Traditional models, once fine-tuned, may struggle to adapt to these changes without retraining, leading to performance degradation over time.
- Blind Spots in Training Data: Fine-tuning models on fixed datasets can create blind spots for edge cases or emerging trends. This limits the model's ability to generalize to new inputs. For example, a sentiment analysis model trained on pre-2020 data might struggle with COVID-19-related terms like "social distancing" or "lockdowns," as these were absent from the original training data.
- Static Context: Even worse, once a model is trained, its understanding of the training data is locked in. It becomes difficult to trace which specific data points influenced the outcome of any given inference, reducing transparency and complicating debugging or audits.
Traditional approaches to address these challenges, such as post-training modifications or additional context injection, often fall short. They treat learned representations as static, lacking the flexibility to adjust to new data or detect shifts in real-time dynamically.
Proposed Solution
Orca enables building classification models with retrieval-augmentation. While you may have heard of RAG (retrieval-augmented generation) in the context of LLMs, Orca extends the ability to inject relevant contextual information to “classical” deep learning models. With Orca, retrieval-augmentation can be applied to different model types, including classification models. We call this a “Retrieval-augmented classifier” or a RAC model.
RAC models retrieve labeled memories that are relevant to the given input from a vector database via semantic search. We can directly use these as a few shot predictor by taking the majority label of the k-nearest-neighbors (KNN). While KNN can produce surprisingly good results in certain scenarios, Orca developed a memory-mixture-of-expert (MMOE) approach which matches state-of-the-art classifier performance and generalizes better. MMOE models injects the memory embeddings and labels into the model alongside the original input embeddings and apply a cross-attention mechanism that learns how to weigh the memories based on a given inputs for the specific task. Because the predictions of KNN and MMOE models are guided by memories, their behavior can be changed in real-time by simply updating the attached memory-set.
Orca’s approach differs from existing methods in the following ways:
- Retrieval-Augmented Inference: Instead of relying solely on statically-vlearned parameters to make inferences for a given input, Orca models retrieve memories similar to the input from an external vector database and use those to guide the output.
- Cross-Attention Mechanism: Orca models go beyond a few-shot approach without trainable parameters and use cross-attention to learn which memories to pay attention to based on a given input and can match state-of-the-art performance.
- Data Traceability: Because the output of Orca models is determined by the memories they retrieve, it becomes possible to trace what data is responsible for any given prediction. This opens the door for much more targeted data optimization.
- Real-time Model Updates: Because the predictions of Orca models are guided by memories the behavior of a model can be changed without retraining by simply changing the memories, enabling models to adapt to changing circumstances in real-time.
Orca models distinguish between logic (identifying sentiment-bearing elements) and data (finding similar samples from the training data). This separation provides complete transparency into which data points influence each prediction and allows for model behavior updates without retraining.
Benchmarking Setup
Let’s consider a real-world example. Let’s say you are an airline and want to monitor how people are talking about your brand on social media. You would train a model to classify the sentiment in social media posts into positive, neutral, and negative and then use that to monitor a business metric. Now let’s say something unexpected happens, like a major hurricane, and all flights are delayed. We see a huge dip in our NPS metric but it isn’t reflecting what we are really interested in anymore. We’d like to quickly change our model to temporarily ignore any flight-delay-related negative sentiment. With an Orca-enabled model, you can simply relabel the delay-related memories of our model to be neutral — no retraining required.
Dataset: To simulate this scenario, we used the Airline Sentiment Dataset, a well-known sentiment classification dataset containing real tweets about airlines that are labeled as positive, negative, or neutral, along with another label describing the reason for negative sentiment. We discarded any samples where the labelers could not agree on a sentiment from the dataset, as those just introduce noise and do not significantly change results. The dataset is split 80%/20% into a training dataset (8356 samples) and testing dataset (2089 samples).
Models: We used Orca to train a retrieval-augmented KNN and MMOE classifier, as well as a baseline model with a feed-forward (FF) classification head with the same number of parameters as the MMOE head. The input to all models were 768-dimensional embeddings generated with Alibaba’s GTE-large-en-v1.5 model, which is small but tends to perform excellently on this task without requiring fine-tuning. The same model was used for memory retrieval based on cosine similarity between the input and memory embeddings. The memoryset consisted of the data from the trainset which generally works well as a starting point. For the KNN model we retrieved five similar memories for each input and 25 memories for the MMOE model.
Metrics: We computed the accuracy and weighted average f1-score on the testset. Then we set the labels for all delay-related samples in the testset to neutral and recomputed the same metrics. To adapt the KNN and MMOE model, we changed the labels of delay-related memories to neutral and recomputed the metrics, we also compared these results against the results achieved by retraining the FF and MMOE models on a trainset with the adapted labels.
Results
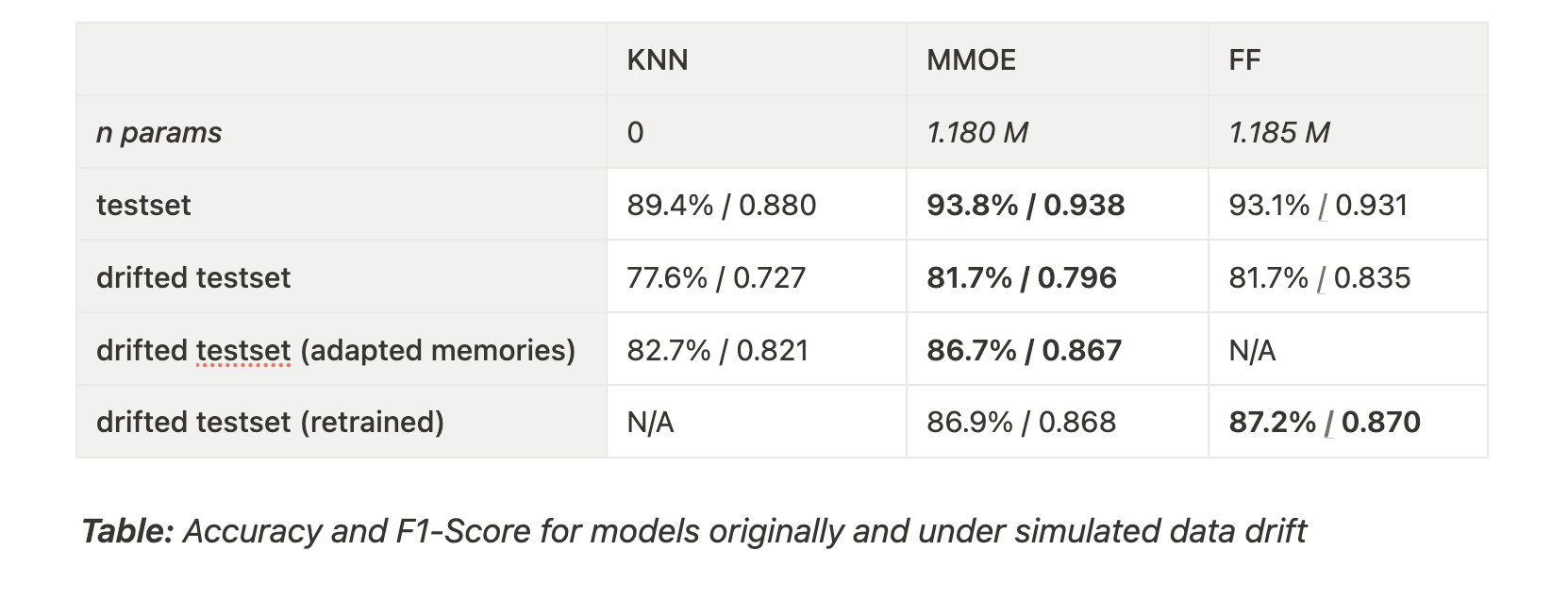
All models make pretty balanced predictions, so we will focus on accuracy in our discussion of the results. (You can see the f1-scores in the table below.) The MMOE model achieves slightly better performance than the FF baseline model. Both are about 4% more accurate than the KNN model. All models can predict the NPS score within one point.
When we simulate the drift, the model’s accuracy degrades by about 12%. By just updating the memoryset of the MMOE classifier it can recover 5% accuracy which is just 0.5% less than what we can achieve by fully retraining the baseline model.
Implications
Orca’s retrieval-augmented classification models have broad applications beyond sentiment analysis, offering significant benefits in various text and image classification tasks. The ability to combat data drift without retraining is invaluable for machine learning teams working in dynamic environments.
- For example, in spam detection scenarios, spammers constantly adapt their techniques to bypass filters, leading to data drift. RAC models can quickly adjust to new spam patterns by updating the memory sets with recent examples, maintaining high detection rates without the need for frequent retraining.
- In product recommendation systems, user preferences can shift rapidly due to trends or seasonal changes. By updating memories with the latest user behavior data, RAC models can provide more accurate and timely recommendations, enhancing user engagement and satisfaction.
- In medical image analysis, transparency is crucial for both performance and trust. RAC models can provide insights into which specific past cases (memories) influenced a diagnosis prediction. For example, when a model identifies a tumor in an MRI scan, it can also highlight the similar images from its memory that contributed to this prediction. This allows doctors to validate predictions and helps machine learning engineers identify the root cause of misclassifications. This not only boosts adaptability but also fosters trust in AI-assisted diagnoses, which is essential in healthcare settings.
The transparency of data usage in Orca’s models also opens up avenues for significant accuracy improvements. Since predictions are directly influenced by specific retrieved memories, machine learning teams can analyze which data points are impacting decisions. This insight enables targeted data optimization—such as identifying and correcting biases, augmenting underrepresented classes, or refining memory quality—which can lead to substantial performance gains in real-world applications.
By extending retrieval-augmented classification to diverse areas, organizations can build models that are not only adaptable to changing data landscapes but also provide clear insights into their decision-making processes. This approach empowers machine learning teams to enhance model accuracy continuously and efficiently, ultimately delivering more reliable and effective solutions across various industries.
.png)


.png)





.png)
