Customizable, low-latency online LLM/Agentic Eval
Agentic/LLM systems need to be controlled while they’re taking action, not just retrospectively examined for mistakes and accuracy. More broadly, good agentic systems engineering practice requires each subsystem be instrumented with both visibility and control - it follows that every input and output of an LLM should be assessed, learned from, and, as appropriate, acted on.
Most are familiar with evaluating LLM output for toxicity and input for jailbreaks and format, but many more assessments are needed for both security and business, including brand alignment, topic adherence, confidence rating, compliance, PII detection, doublecheck/human involvement flagging, etc.
Often, the correct evaluation criteria depends on the specifics of an individual prompt and who/what is doing the prompting. Current solutions suffer from high latency/cost (using smaller LLMs), cumbersome customization and retraining/tuning (classic classifiers), or high complexity/cost and lagging update (policy/rule engines). Orca provides the benefits of all three approaches without the painful tradeoffs.
Low Latency
Often, even state-of-the-art guardrail solutions introduce problematic latency into agentic and LLM-based systems, especially when these systems handle high volumes and/or are user-facing. These penalties force teams into a no-win choice between pushing evaluations offline for retrospective clean-up or accepting less effective evaluations to triage safety & alignment.
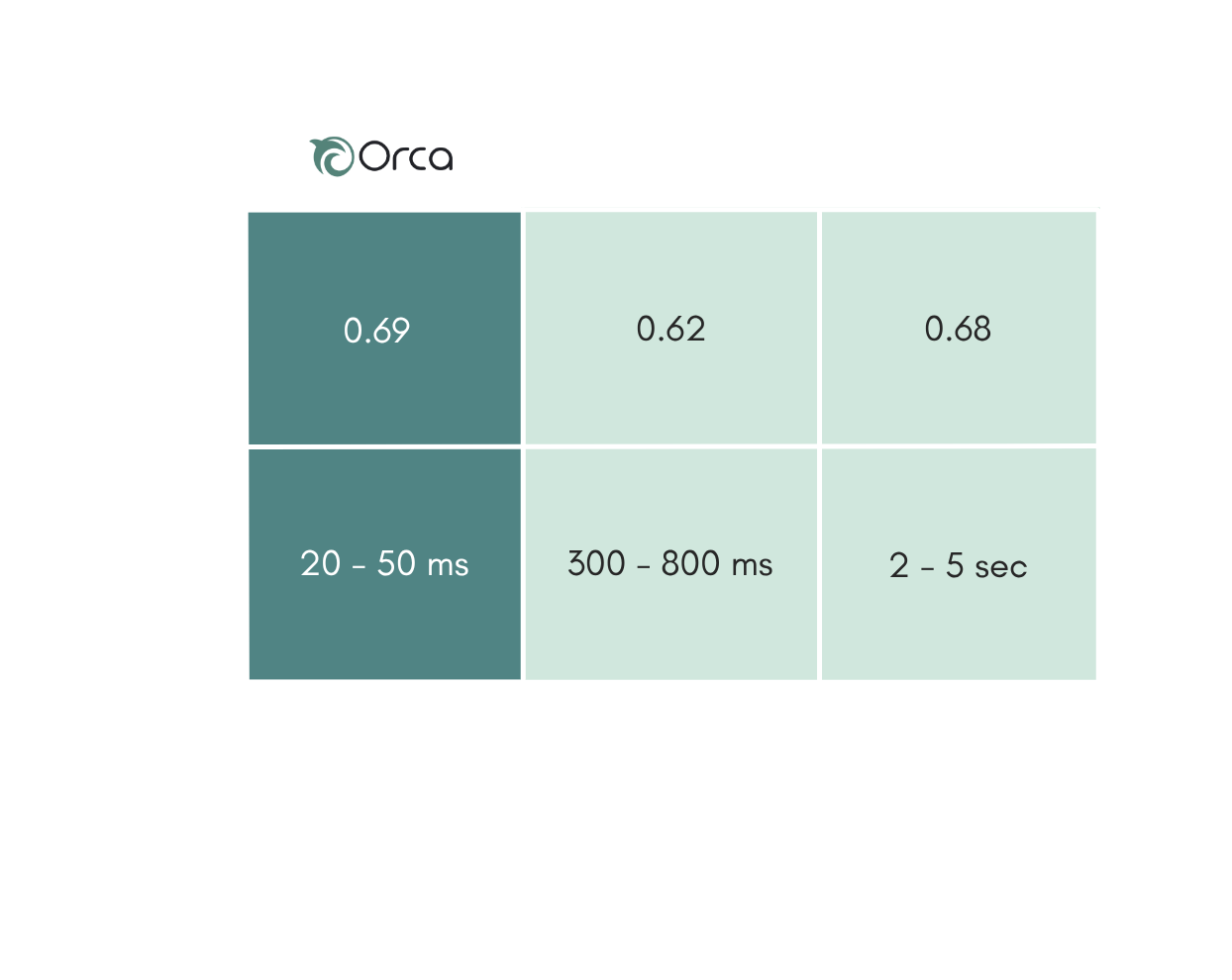
One example is comparing Orca and LlamaGuard for toxicity detection using standard benchmark datasets. Orca delivers better accuracy but 30-50 times lower latency.
Customization
Given there are so many dimensions needed to properly instrument and score the inputs and outputs to an LLM, many Enterprises are forced into hard tradeoffs - LLMs are flexible but non-determistic, slow, and costly at scale; “classic” classification models are faster but require many models and/or complex & laggy conditional steering logic. Orca enables customized evaluation of inputs and outputs not only for broad context (topic, customer/user, geo, etc.) but also for the specific prompt or output associated with each inference (e.g. prompt includes sensitive design information that may be protected IP). In addition, a single model can cover the complete array of business and security evaluations by simply swapping memorysets for each inference to cover all of the different evaluation criteria. For example, a single model could conditionally apply geo-specific PII evaluation, jailbreaking, toxicity, and brand alignment by swapping to a memoryset corresponding to each use case.
Talk to Orca
Speak to our engineering team to learn how we can help you unlock high performance agentic AI / LLM evaluation, real-time adaptive ML, and accelerated AI operations.